R version 4.2.2 (2022-10-31)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Big Sur ... 10.16
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] Rcpp_1.0.9 here_1.0.1 lattice_0.20-45 png_0.1-8
[5] rprojroot_2.0.3 digest_0.6.30 grid_4.2.2 lifecycle_1.0.3
[9] jsonlite_1.8.4 magrittr_2.0.3 evaluate_0.18 rlang_1.0.6
[13] stringi_1.7.8 cli_3.4.1 rstudioapi_0.14 Matrix_1.5-1
[17] reticulate_1.26 vctrs_0.5.1 rmarkdown_2.18 tools_4.2.2
[21] stringr_1.5.0 glue_1.6.2 htmlwidgets_1.6.0 xfun_0.35
[25] yaml_2.3.6 fastmap_1.1.0 compiler_4.2.2 htmltools_0.5.4
[29] knitr_1.41
1 Overview
We illustrate the typical machine learning workflow for regression problems using the Default data set from R ISLR2 package. Our goal is to classify whether a credit card customer will default or not. The steps are
Initial splitting to test and non-test sets.
Pre-processing of data: one-hot-encoder for categorical variables, add nonlinear features (B-splines) for some continuous predictors.
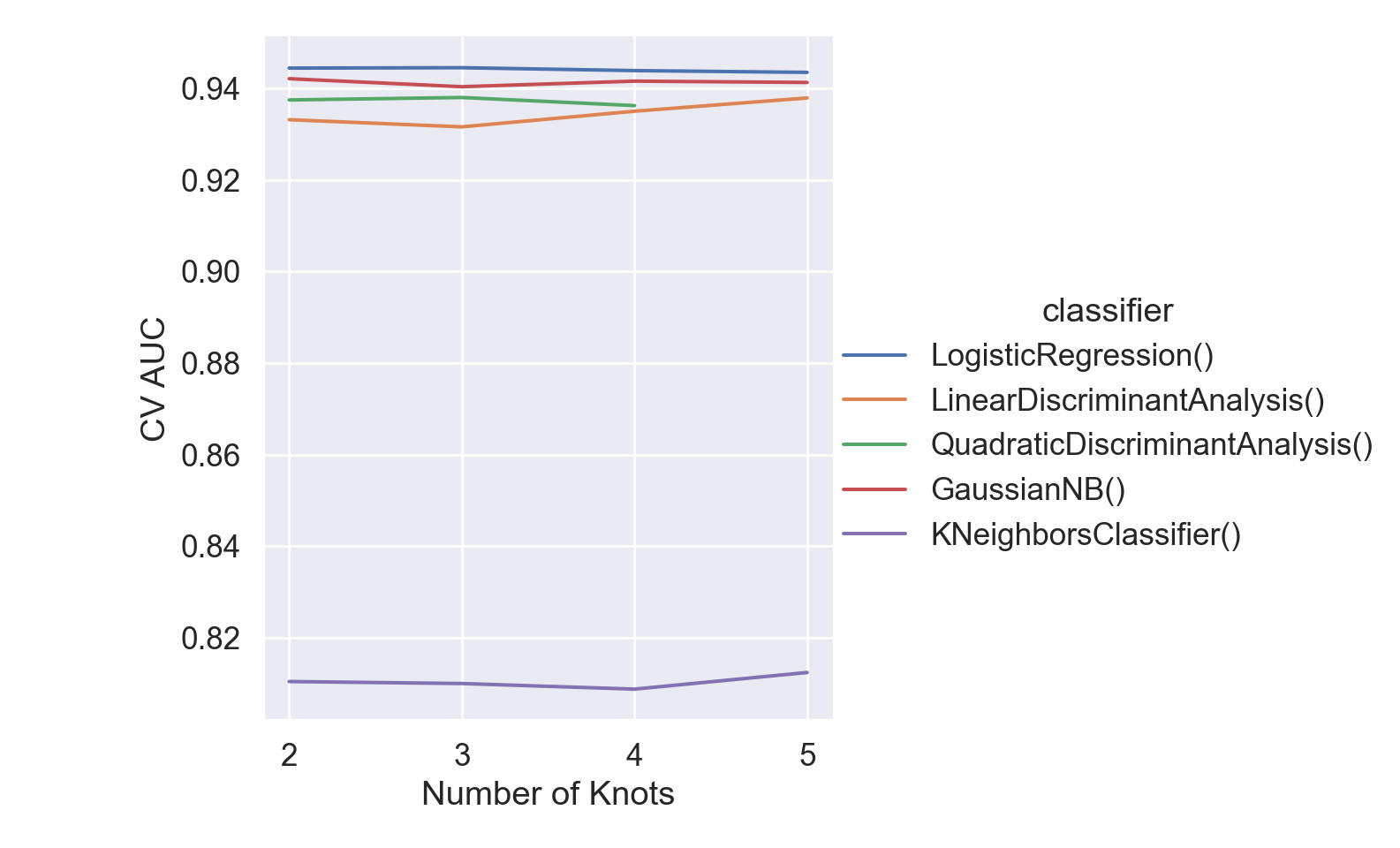
Choose a set of candidate classifiers: logistic regression, LDA, QDA, NB, KNN.
Tune the hyper-parameter(s) (n_knots in SplineTransformer, classifier) using 10-fold cross-validation (CV) on the non-test data.
Choose the best model by CV and refit it on the whole non-test data.
Final classification on the test data.
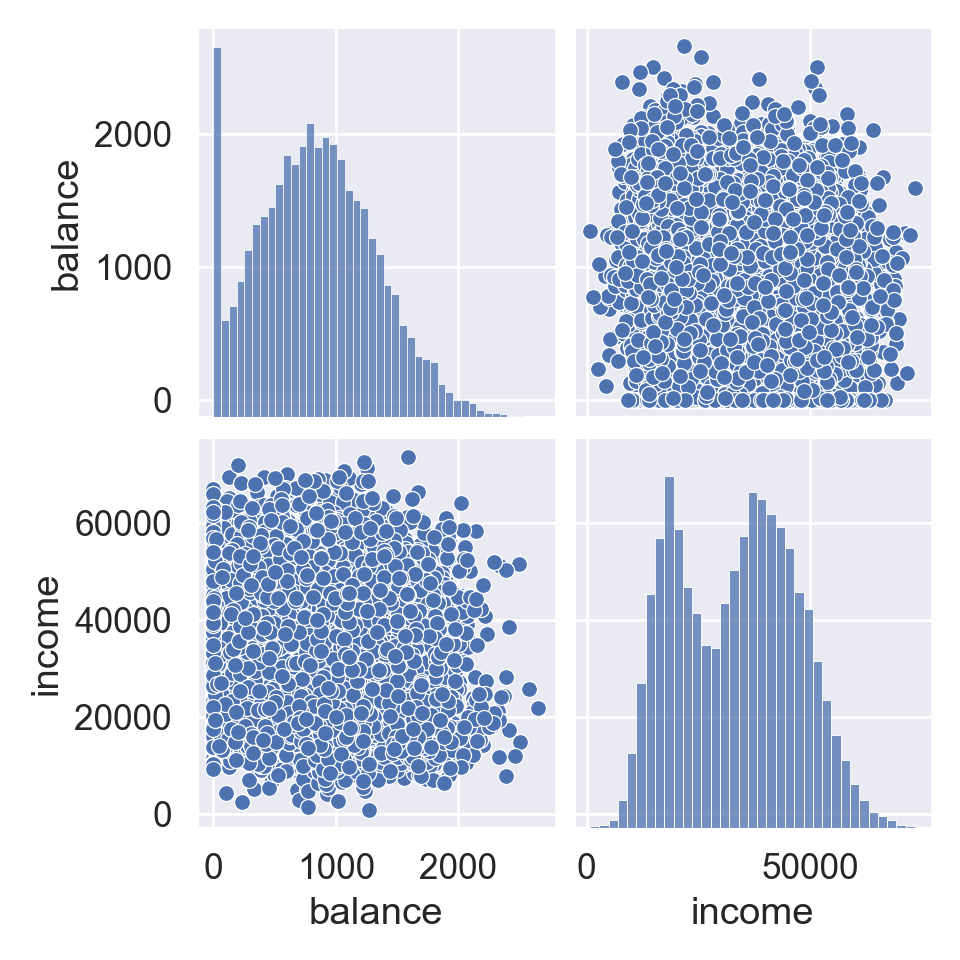
2 Default data
A documentation of the Default data is here. The goal is to classify whether a credit card customer will default or not.
# Load the pandas libraryimport pandas as pd# Load numpy for array manipulationimport numpy as np# Load seaborn plotting libraryimport seaborn as snsimport matplotlib.pyplot as plt# Set font sizes in plotssns.set(font_scale =1.2)# Display all columnspd.set_option('display.max_columns', None)Default = pd.read_csv("../data/Default.csv")Default
default student balance income
0 No No 729.526495 44361.625074
1 No Yes 817.180407 12106.134700
2 No No 1073.549164 31767.138947
3 No No 529.250605 35704.493935
4 No No 785.655883 38463.495879
... ... ... ... ...
9995 No No 711.555020 52992.378914
9996 No No 757.962918 19660.721768
9997 No No 845.411989 58636.156984
9998 No No 1569.009053 36669.112365
9999 No Yes 200.922183 16862.952321
[10000 rows x 4 columns]
# Numerical summariesDefault.describe()
balance income
count 10000.000000 10000.000000
mean 835.374886 33516.981876
std 483.714985 13336.639563
min 0.000000 771.967729
25% 481.731105 21340.462903
50% 823.636973 34552.644802
75% 1166.308386 43807.729272
max 2654.322576 73554.233495
# A tibble: 10,000 × 4
default student balance income
<fct> <fct> <dbl> <dbl>
1 No No 730. 44362.
2 No Yes 817. 12106.
3 No No 1074. 31767.
4 No No 529. 35704.
5 No No 786. 38463.
6 No Yes 920. 7492.
7 No No 826. 24905.
8 No Yes 809. 17600.
9 No No 1161. 37469.
10 No No 0 29275.
# … with 9,990 more rows
# Numerical summariessummary(Default)
default student balance income
No :9667 No :7056 Min. : 0.0 Min. : 772
Yes: 333 Yes:2944 1st Qu.: 481.7 1st Qu.:21340
Median : 823.6 Median :34553
Mean : 835.4 Mean :33517
3rd Qu.:1166.3 3rd Qu.:43808
Max. :2654.3 Max. :73554
# Non-test X and yX_other = Default_other[['balance', 'income', 'student']]y_other = Default_other.default# Test X and yX_test = Default_test[['balance', 'income', 'student']]y_test = Default_test.default
# For reproducibilityset.seed(425)data_split <-initial_split( Wage, # # stratify by percentiles# strata = "Salary", prop =0.75 )Wage_other <-training(data_split)dim(Wage_other)Wage_test <-testing(data_split)dim(Wage_test)
norm_recipe <-recipe( wage ~ year + age + education, data = Wage_other ) %>%# create traditional dummy variablesstep_dummy(all_nominal()) %>%# zero-variance filterstep_zv(all_predictors()) %>%# B-splines of agestep_bs(age, deg_free =5) %>%# B-splines of yearstep_bs(year, deg_free =4) %>%# center and scale numeric datastep_normalize(all_predictors()) %>%# estimate the means and standard deviationsprep(training = Wage_other, retain =TRUE)norm_recipe
5 Model
Let’s skip this step for now, because the model (or classifer) itself is being tuned by CV.
Here we bundle the preprocessing step (Python) or recipe (R) and model. Again remember KNN is a placeholder here. Later we will choose the better classifier according to cross validation.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Set up CV partitions and CV criterion. Again it’s a good idea to keep the case proportions roughly same between splits. According to the GridSearchCVdocumentation, StratifiedKFold is used automatically.
from sklearn.model_selection import GridSearchCV# Set up CVn_folds =10search = GridSearchCV( pipe, tuned_parameters, cv = n_folds, scoring ="roc_auc",# Refit the best model on the whole data set refit =True )
Fit CV. This is typically the most time-consuming step.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Now we are done tuning. Finally, let’s fit this final model to the whole training data and use our test data to estimate the model performance we expect to see with new data.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
from sklearn.metrics import roc_auc_scoreroc_auc_score( y_test, search.best_estimator_.predict_proba(X_test)[:, 1] )
0.9648772998489614
# Final workflowfinal_wf <- lr_wf %>%finalize_workflow(best_enet)final_wf# Fit the whole training set, then predict the test casesfinal_fit <- final_wf %>%last_fit(data_split)final_fit# Test metricsfinal_fit %>%collect_metrics()