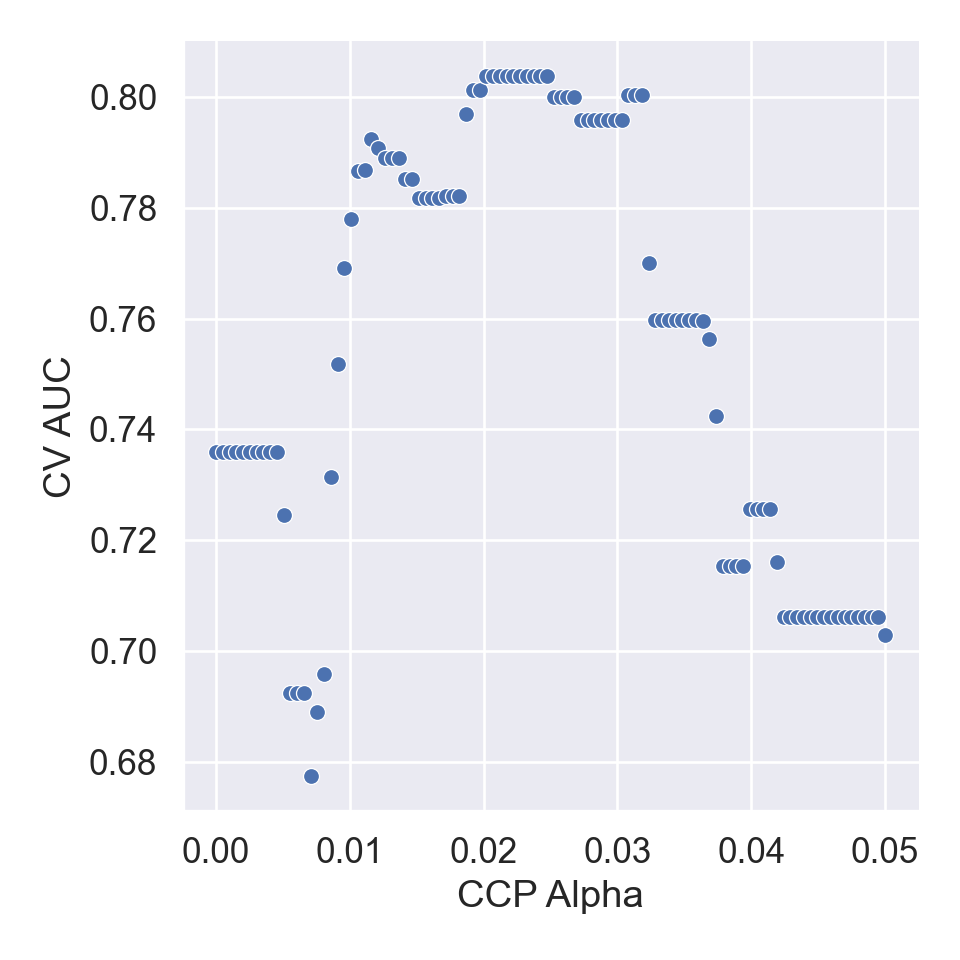
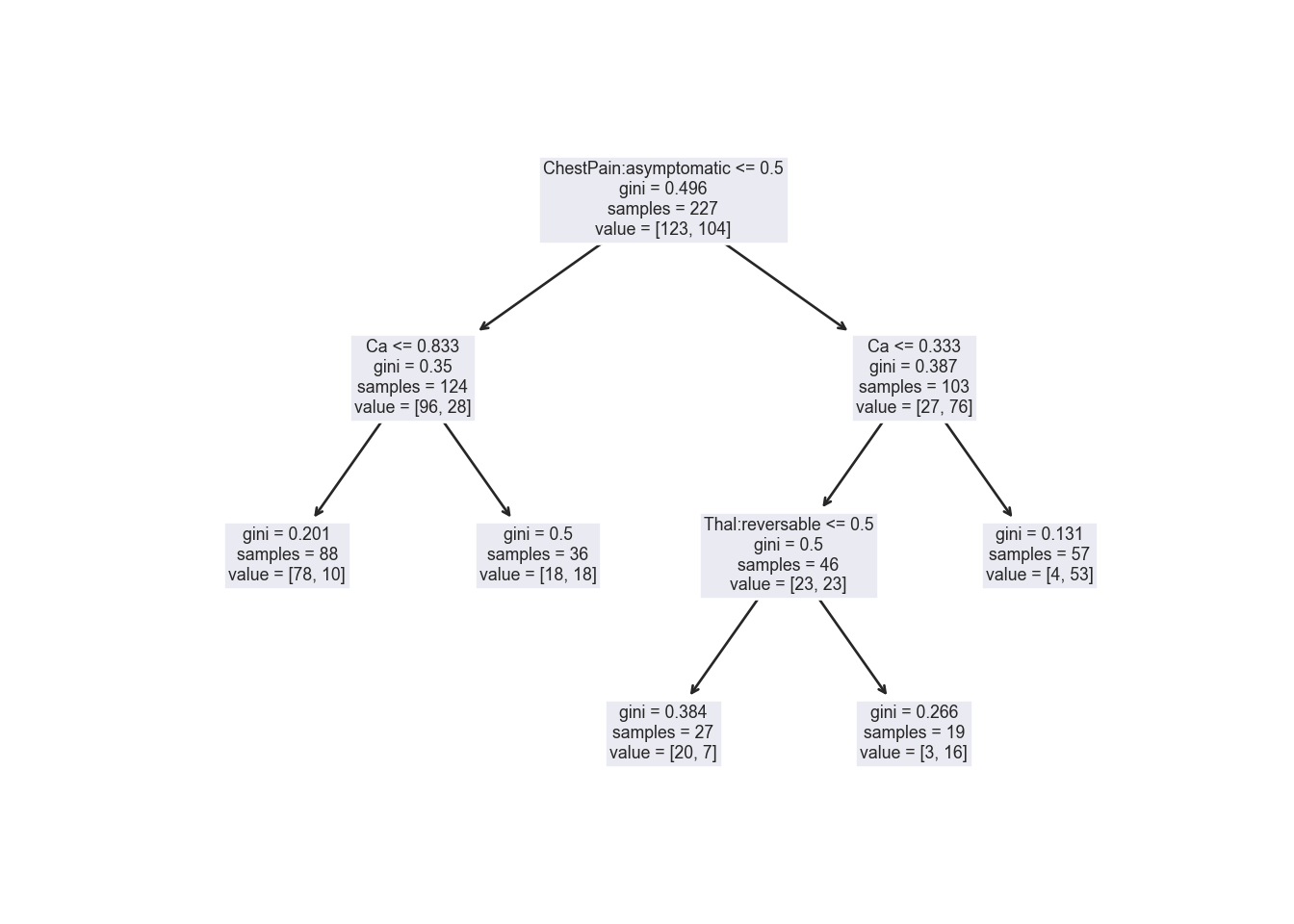
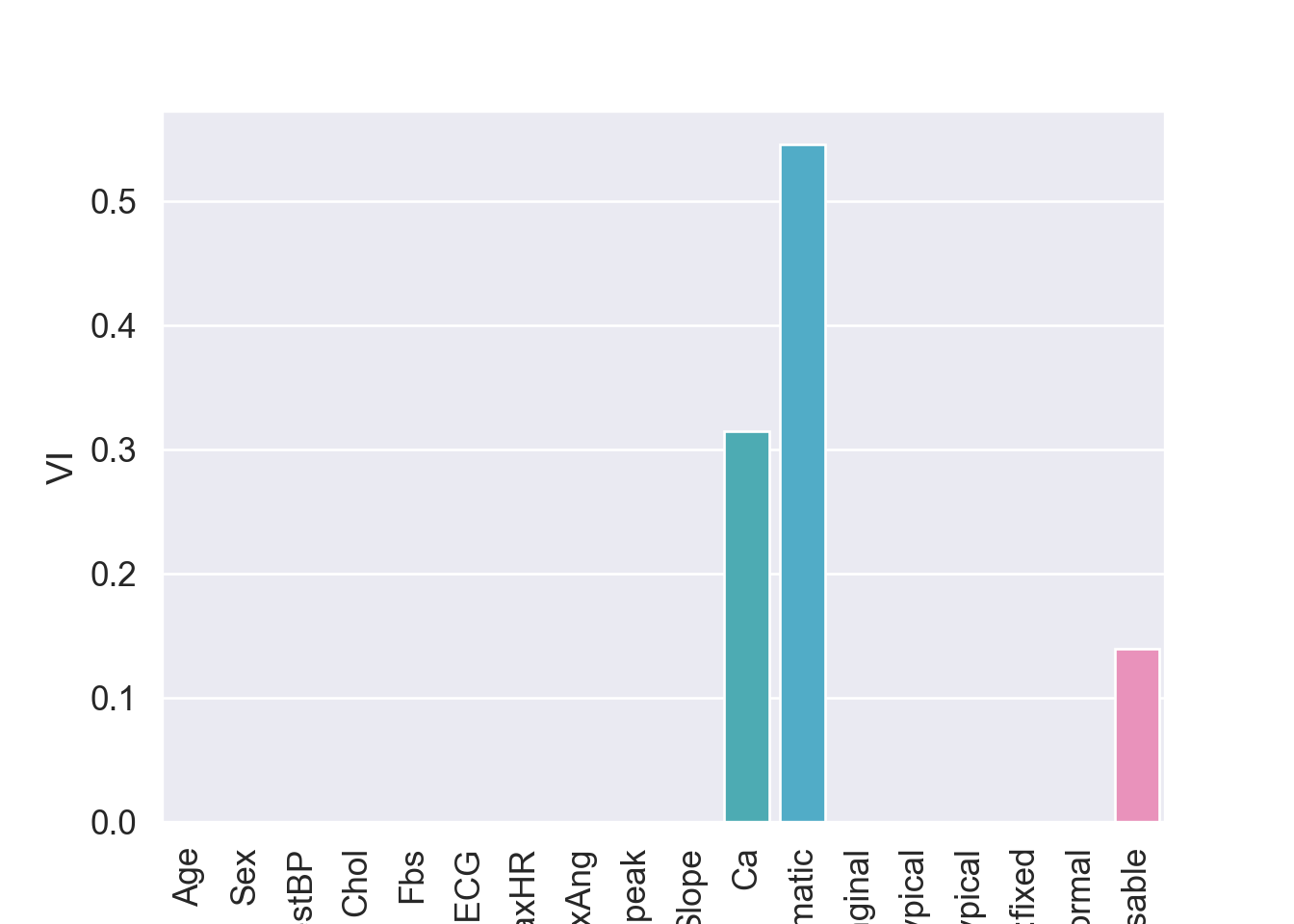
{'model__ccp_alpha': array([0. , 0.00050505, 0.0010101 , 0.00151515, 0.0020202 ,
0.00252525, 0.0030303 , 0.00353535, 0.0040404 , 0.00454545,
0.00505051, 0.00555556, 0.00606061, 0.00656566, 0.00707071,
0.00757576, 0.00808081, 0.00858586, 0.00909091, 0.00959596,
0.01010101, 0.01060606, 0.01111111, 0.01161616, 0.01212121,
0.01262626, 0.01313131, 0.01363636, 0.01414141, 0.01464646,
0.01515152, 0.01565657, 0.01616162, 0.01666667, 0.01717172,
0.01767677, 0.01818182, 0.01868687, 0.01919192, 0.01969697,
0.02020202, 0.02070707, 0.02121212, 0.02171717, 0.02222222,
0.02272727, 0.02323232, 0.02373737, 0.02424242, 0.02474747,
0.02525253, 0.02575758, 0.02626263, 0.02676768, 0.02727273,
0.02777778, 0.02828283, 0.02878788, 0.02929293, 0.02979798,
0.03030303, 0.03080808, 0.03131313, 0.03181818, 0.03232323,
0.03282828, 0.03333333, 0.03383838, 0.03434343, 0.03484848,
0.03535354, 0.03585859, 0.03636364, 0.03686869, 0.03737374,
0.03787879, 0.03838384, 0.03888889, 0.03939394, 0.03989899,
0.04040404, 0.04090909, 0.04141414, 0.04191919, 0.04242424,
0.04292929, 0.04343434, 0.04393939, 0.04444444, 0.04494949,
0.04545455, 0.0459596 , 0.04646465, 0.0469697 , 0.04747475,
0.0479798 , 0.04848485, 0.0489899 , 0.04949495, 0.05 ])}