We illustrate the typical machine learning workflow for random forests using the Hitters data set from R ISLR2 package.
Initial splitting to test and non-test sets.
Pre-processing of data: not much is needed for regression trees.
Tune the cost complexity pruning hyper-parameter(s) using 10-fold cross-validation (CV) on the non-test data.
Choose the best model by CV and refit it on the whole non-test data.
Final prediction on the test data.
2 Hitters data
A documentation of the Hitters data is here. The goal is to predict the log(Salary) (at opening of 1987 season) of MLB players from their performance metrics in the 1986-7 season.
# Load the pandas libraryimport pandas as pd# Load numpy for array manipulationimport numpy as np# Load seaborn plotting libraryimport seaborn as snsimport matplotlib.pyplot as plt# Set font sizes in plotssns.set(font_scale =1.2)# Display all columnspd.set_option('display.max_columns', None)Hitters = pd.read_csv("../data/Hitters.csv")Hitters
AtBat Hits HmRun Runs RBI Walks Years CAtBat CHits CHmRun \
0 293 66 1 30 29 14 1 293 66 1
1 315 81 7 24 38 39 14 3449 835 69
2 479 130 18 66 72 76 3 1624 457 63
3 496 141 20 65 78 37 11 5628 1575 225
4 321 87 10 39 42 30 2 396 101 12
.. ... ... ... ... ... ... ... ... ... ...
317 497 127 7 65 48 37 5 2703 806 32
318 492 136 5 76 50 94 12 5511 1511 39
319 475 126 3 61 43 52 6 1700 433 7
320 573 144 9 85 60 78 8 3198 857 97
321 631 170 9 77 44 31 11 4908 1457 30
CRuns CRBI CWalks League Division PutOuts Assists Errors Salary \
0 30 29 14 A E 446 33 20 NaN
1 321 414 375 N W 632 43 10 475.0
2 224 266 263 A W 880 82 14 480.0
3 828 838 354 N E 200 11 3 500.0
4 48 46 33 N E 805 40 4 91.5
.. ... ... ... ... ... ... ... ... ...
317 379 311 138 N E 325 9 3 700.0
318 897 451 875 A E 313 381 20 875.0
319 217 93 146 A W 37 113 7 385.0
320 470 420 332 A E 1314 131 12 960.0
321 775 357 249 A W 408 4 3 1000.0
NewLeague
0 A
1 N
2 A
3 N
4 N
.. ...
317 N
318 A
319 A
320 A
321 A
[322 rows x 20 columns]
Separate \(X\) and \(y\). We will use 9 of the features.
features = ['Assists', 'AtBat', 'Hits', 'HmRun', 'PutOuts', 'RBI', 'Runs', 'Walks', 'Years']# Non-test X and yX_other = Hitters_other[features]y_other = np.log(Hitters_other.Salary)# Test X and yX_test = Hitters_test[features]y_test = np.log(Hitters_test.Salary)
from sklearn.ensemble import RandomForestRegressorrf_mod = RandomForestRegressor(# Number of trees n_estimators =100, criterion ='squared_error',# Number of features to use in each split max_features ='sqrt', oob_score =True, random_state =425 )
6 Pipeline (Python) or workflow (R)
Here we bundle the preprocessing step (Python) or recipe (R) and model.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
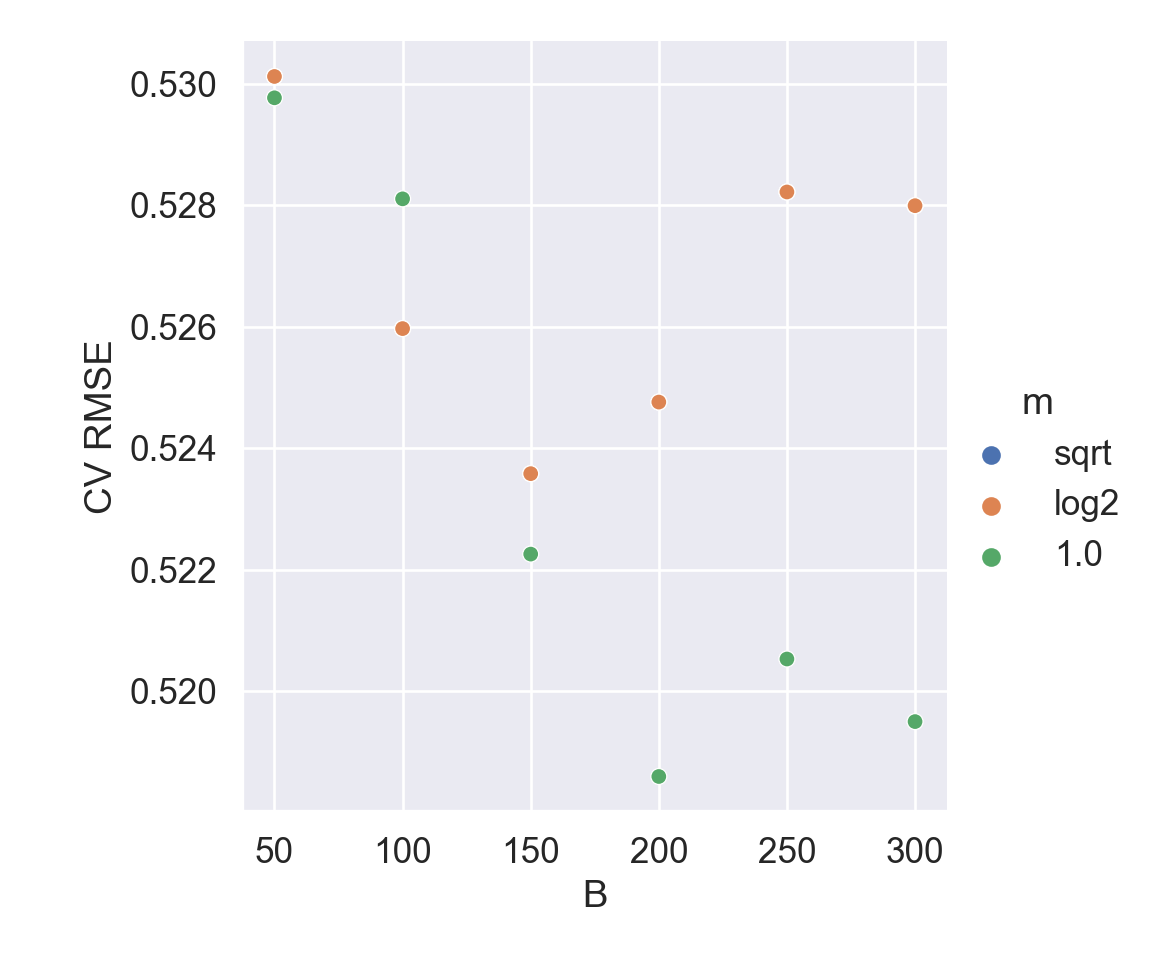
In general, it’s not necessary to tune a random forest. Using the default of n_estimators=100 and max_features=1.0 (bagging) or max_features='sqrt' works well.
Here we tune the number of trees n_estimators and the number of features to use in each split max_features.
from sklearn.model_selection import GridSearchCV# Set up CVn_folds =6search = GridSearchCV( pipe, tuned_parameters, cv = n_folds, scoring ="neg_root_mean_squared_error",# Refit the best model on the whole data set refit =True )
Fit CV. This is typically the most time-consuming step.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
cv_res = pd.DataFrame({"B": np.array(search.cv_results_["param_model__n_estimators"]),"rmse": -search.cv_results_["mean_test_score"],"m": search.cv_results_["param_model__max_features"] })plt.figure()sns.relplot(# kind = "line", data = cv_res, x ="B", y ="rmse", hue ="m", ).set( xlabel ="B", ylabel ="CV RMSE");plt.show()
Best CV RMSE:
-search.best_score_
0.5185992261269462
9 Finalize our model
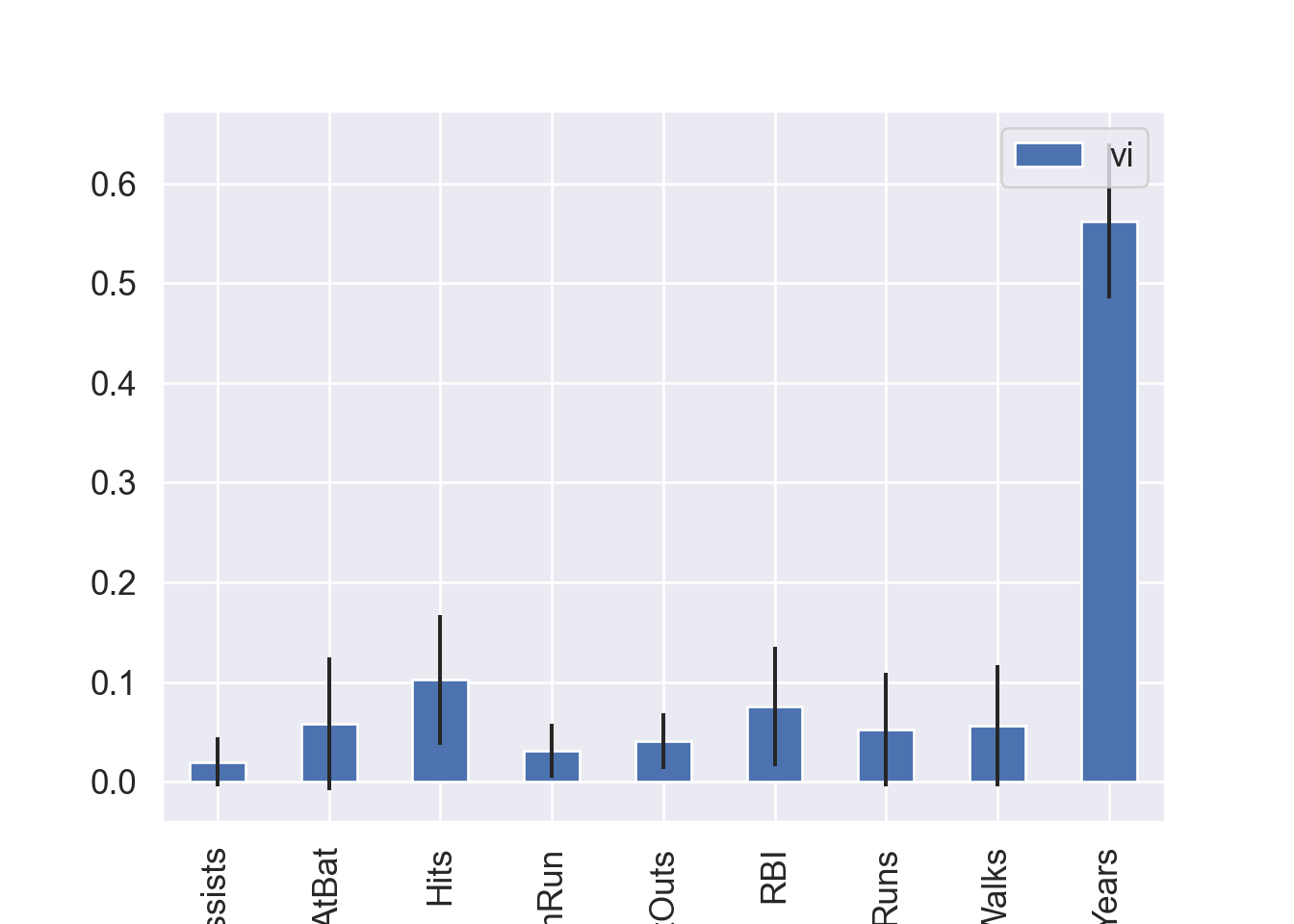
Now we are done tuning. Finally, let’s fit this final model to the whole training data and use our test data to estimate the model performance we expect to see with new data.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
vi_df = pd.DataFrame({"feature": features,"vi": search.best_estimator_['model'].feature_importances_,"vi_std": np.std([tree.feature_importances_ for tree in search.best_estimator_['model'].estimators_], axis =0) })plt.figure()vi_df.plot.bar(x ="feature", y ="vi", yerr ="vi_std")plt.xticks(rotation =90);plt.show()
The final prediction RMSE on the test set is
from sklearn.metrics import mean_squared_errormean_squared_error( y_test, search.best_estimator_.predict(X_test), squared =False )