Display system information for reproducibility.
import IPythonprint (IPython.sys_info())
{'commit_hash': 'add5877a4',
'commit_source': 'installation',
'default_encoding': 'utf-8',
'ipython_path': '/Users/huazhou/opt/anaconda3/lib/python3.9/site-packages/IPython',
'ipython_version': '8.8.0',
'os_name': 'posix',
'platform': 'macOS-10.16-x86_64-i386-64bit',
'sys_executable': '/Users/huazhou/opt/anaconda3/bin/python3',
'sys_platform': 'darwin',
'sys_version': '3.9.12 (main, Apr 5 2022, 01:56:13) \n[Clang 12.0.0 ]'}
R version 4.2.2 (2022-10-31)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Big Sur ... 10.16
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] Rcpp_1.0.9 here_1.0.1 lattice_0.20-45 png_0.1-8
[5] withr_2.5.0 rprojroot_2.0.3 digest_0.6.29 grid_4.2.2
[9] jsonlite_1.8.0 magrittr_2.0.3 evaluate_0.15 rlang_1.0.6
[13] stringi_1.7.8 cli_3.4.1 rstudioapi_0.13 Matrix_1.5-1
[17] reticulate_1.27 rmarkdown_2.14 tools_4.2.2 stringr_1.4.0
[21] htmlwidgets_1.6.1 xfun_0.31 yaml_2.3.5 fastmap_1.1.0
[25] compiler_4.2.2 htmltools_0.5.4 knitr_1.39
Load libraries.
# Plotting tool import matplotlib.pyplot as plt# Load Tensorflow and Keras import tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layers
Prepare data
From documentation:
Dataset of 25,000 movies reviews from IMDB, labeled by sentiment (positive/negative). Reviews have been preprocessed, and each review is encoded as a sequence of word indexes (integers). For convenience, words are indexed by overall frequency in the dataset, so that for instance the integer “3” encodes the 3rd most frequent word in the data. This allows for quick filtering operations such as: “only consider the top 10,000 most common words, but eliminate the top 20 most common words”.
Retrieve IMDB data:
= 10000 # to be consistent with lasso example # Cut texts after this number of words (among top max_features most common words) = 80 = 32 print ('Loading data...' )= keras.datasets.imdb.load_data(= max_features
Sizes of training and test sets:
print (len (x_train), 'train sequences' )print (len (x_test), 'test sequences' )
We pad texts to maxlen=80 words.
print ('Pad sequences (samples x time)' )
Pad sequences (samples x time)
= keras.preprocessing.sequence.pad_sequences(x_train, maxlen = maxlen)= keras.preprocessing.sequence.pad_sequences(x_test, maxlen = maxlen)print ('x_train shape:' , x_train.shape)
x_train shape: (25000, 80)
print ('x_test shape:' , x_test.shape)
x_test shape: (25000, 80)
<- 10000 # to be consistent with lasso example # Cut texts after this number of words (among top max_features most common words) <- 80 cat ('Loading data... \n ' )<- dataset_imdb (num_words = max_features)$ train$ x[[1 ]]
[1] 1 14 22 16 43 530 973 1622 1385 65 458 4468 66 3941 4
[16] 173 36 256 5 25 100 43 838 112 50 670 2 9 35 480
[31] 284 5 150 4 172 112 167 2 336 385 39 4 172 4536 1111
[46] 17 546 38 13 447 4 192 50 16 6 147 2025 19 14 22
[61] 4 1920 4613 469 4 22 71 87 12 16 43 530 38 76 15
[76] 13 1247 4 22 17 515 17 12 16 626 18 2 5 62 386
[91] 12 8 316 8 106 5 4 2223 5244 16 480 66 3785 33 4
[106] 130 12 16 38 619 5 25 124 51 36 135 48 25 1415 33
[121] 6 22 12 215 28 77 52 5 14 407 16 82 2 8 4
[136] 107 117 5952 15 256 4 2 7 3766 5 723 36 71 43 530
[151] 476 26 400 317 46 7 4 2 1029 13 104 88 4 381 15
[166] 297 98 32 2071 56 26 141 6 194 7486 18 4 226 22 21
[181] 134 476 26 480 5 144 30 5535 18 51 36 28 224 92 25
[196] 104 4 226 65 16 38 1334 88 12 16 283 5 16 4472 113
[211] 103 32 15 16 5345 19 178 32
Sizes of training and test sets:
<- imdb$ train$ x<- imdb$ train$ y<- imdb$ test$ x<- imdb$ test$ ycat (length (x_train), 'train sequences \n ' )cat (length (x_test), 'test sequences \n ' )
We pad texts to maxlen=80 words.
cat ('Pad sequences (samples x time) \n ' )
Pad sequences (samples x time)
<- pad_sequences (x_train, maxlen = maxlen)<- pad_sequences (x_test, maxlen = maxlen)cat ('x_train shape:' , dim (x_train), ' \n ' )cat ('x_test shape:' , dim (x_test), ' \n ' )
Build model
= keras.Sequential([128 ),= 64 ),= 1 , activation = 'sigmoid' )# try using different optimizers and different optimizer configs compile (= 'binary_crossentropy' ,= 'adam' ,= ['accuracy' ]
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 128) 1280000
simple_rnn (SimpleRNN) (None, 64) 12352
dense (Dense) (None, 1) 65
=================================================================
Total params: 1,292,417
Trainable params: 1,292,417
Non-trainable params: 0
_________________________________________________________________
<- keras_model_sequential ()%>% layer_embedding (input_dim = max_features, output_dim = 128 ) %>% layer_simple_rnn (units = 64 ) %>% layer_dense (units = 1 , activation = 'sigmoid' )# Try using different optimizers and different optimizer configs %>% compile (loss = 'binary_crossentropy' ,optimizer = 'adam' ,metrics = c ('accuracy' )summary (model)
Model: "sequential_1"
________________________________________________________________________________
Layer (type) Output Shape Param #
================================================================================
embedding_1 (Embedding) (None, None, 128) 1280000
simple_rnn_1 (SimpleRNN) (None, 64) 12352
dense_1 (Dense) (None, 1) 65
================================================================================
Total params: 1,292,417
Trainable params: 1,292,417
Non-trainable params: 0
________________________________________________________________________________
Training
= model.fit(= batch_size,= 15 ,= 0.2 , = 2 # one line per epoch
Epoch 1/15
625/625 - 10s - loss: 0.6023 - accuracy: 0.6636 - val_loss: 0.5142 - val_accuracy: 0.7592 - 10s/epoch - 16ms/step
Epoch 2/15
625/625 - 9s - loss: 0.4032 - accuracy: 0.8206 - val_loss: 0.4833 - val_accuracy: 0.7916 - 9s/epoch - 15ms/step
Epoch 3/15
625/625 - 9s - loss: 0.1895 - accuracy: 0.9292 - val_loss: 0.5974 - val_accuracy: 0.7650 - 9s/epoch - 15ms/step
Epoch 4/15
625/625 - 9s - loss: 0.0654 - accuracy: 0.9793 - val_loss: 0.8400 - val_accuracy: 0.7280 - 9s/epoch - 14ms/step
Epoch 5/15
625/625 - 9s - loss: 0.0273 - accuracy: 0.9918 - val_loss: 0.9126 - val_accuracy: 0.7650 - 9s/epoch - 14ms/step
Epoch 6/15
625/625 - 9s - loss: 0.0334 - accuracy: 0.9887 - val_loss: 1.1902 - val_accuracy: 0.6968 - 9s/epoch - 14ms/step
Epoch 7/15
625/625 - 9s - loss: 0.0427 - accuracy: 0.9852 - val_loss: 0.9505 - val_accuracy: 0.7426 - 9s/epoch - 14ms/step
Epoch 8/15
625/625 - 9s - loss: 0.0309 - accuracy: 0.9901 - val_loss: 1.1198 - val_accuracy: 0.7332 - 9s/epoch - 15ms/step
Epoch 9/15
625/625 - 9s - loss: 0.0147 - accuracy: 0.9952 - val_loss: 1.1105 - val_accuracy: 0.7756 - 9s/epoch - 14ms/step
Epoch 10/15
625/625 - 9s - loss: 0.0326 - accuracy: 0.9886 - val_loss: 1.3681 - val_accuracy: 0.6656 - 9s/epoch - 14ms/step
Epoch 11/15
625/625 - 9s - loss: 0.0403 - accuracy: 0.9863 - val_loss: 1.0803 - val_accuracy: 0.7236 - 9s/epoch - 14ms/step
Epoch 12/15
625/625 - 9s - loss: 0.0191 - accuracy: 0.9945 - val_loss: 1.1680 - val_accuracy: 0.7624 - 9s/epoch - 14ms/step
Epoch 13/15
625/625 - 9s - loss: 0.0071 - accuracy: 0.9978 - val_loss: 1.4750 - val_accuracy: 0.7036 - 9s/epoch - 14ms/step
Epoch 14/15
625/625 - 9s - loss: 0.0338 - accuracy: 0.9875 - val_loss: 1.3892 - val_accuracy: 0.6512 - 9s/epoch - 14ms/step
Epoch 15/15
625/625 - 9s - loss: 0.0387 - accuracy: 0.9859 - val_loss: 1.2856 - val_accuracy: 0.7468 - 9s/epoch - 14ms/step
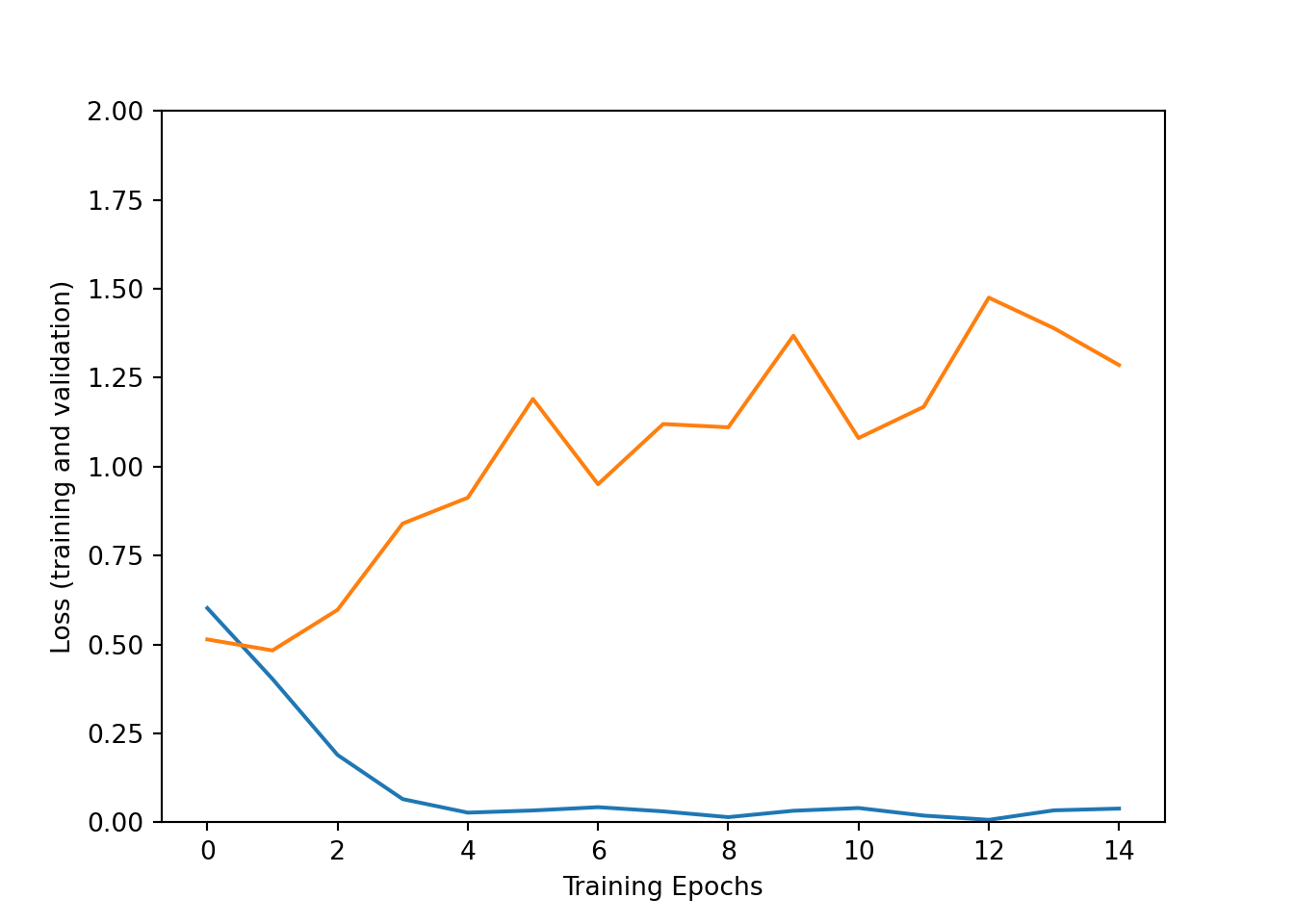
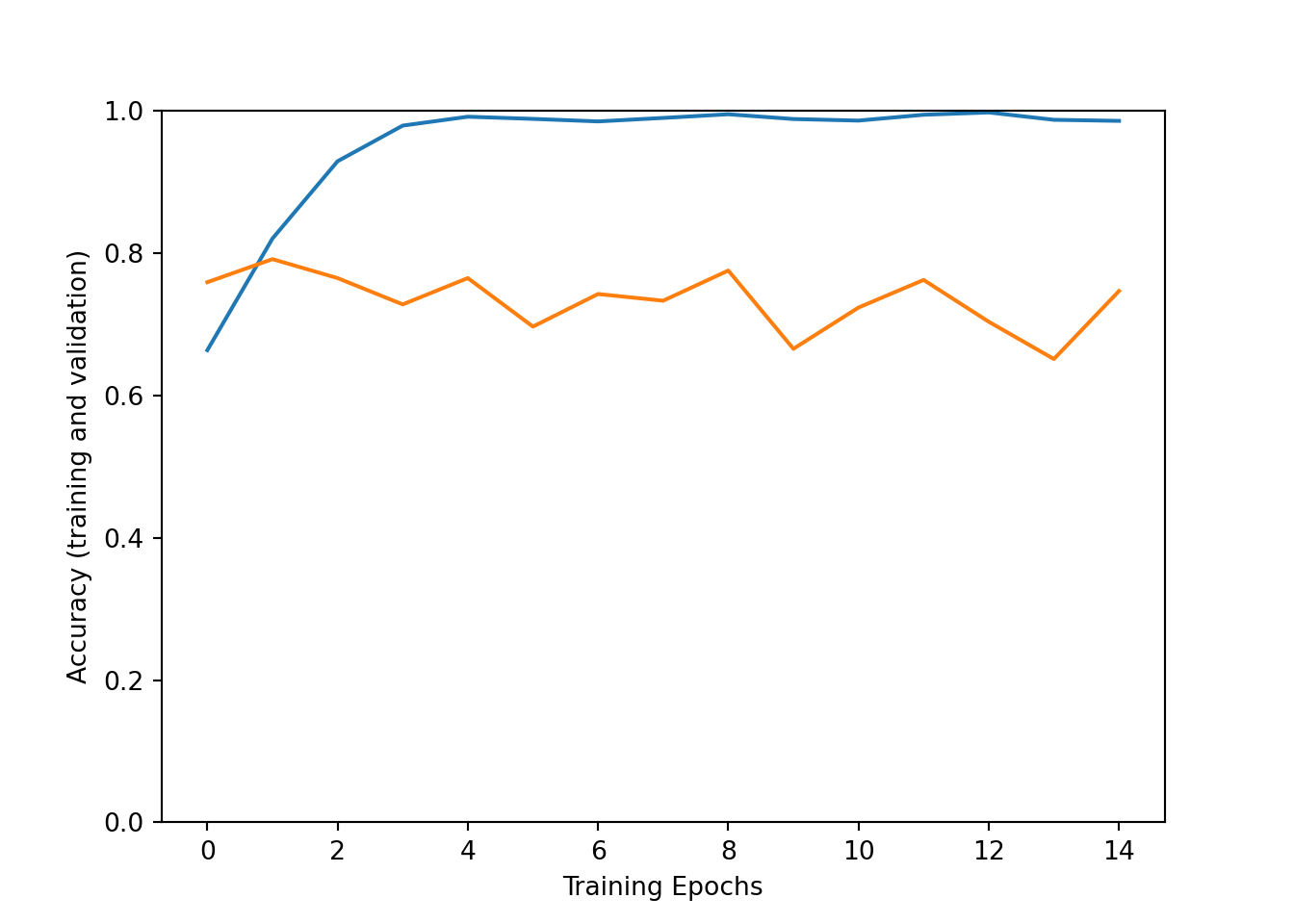
Visualize training process:
"Loss (training and validation)" )"Training Epochs" )0 , 2 ])"loss" ])"val_loss" ])"Accuracy (training and validation)" )"Training Epochs" )0 , 1 ])"accuracy" ])"val_accuracy" ])
<- 32 cat ('Train... \n ' )system.time ({<- model %>% fit (batch_size = batch_size,epochs = 15 ,validation_split = 0.2 ,verbose = 2
user system elapsed
666.241 140.813 137.249
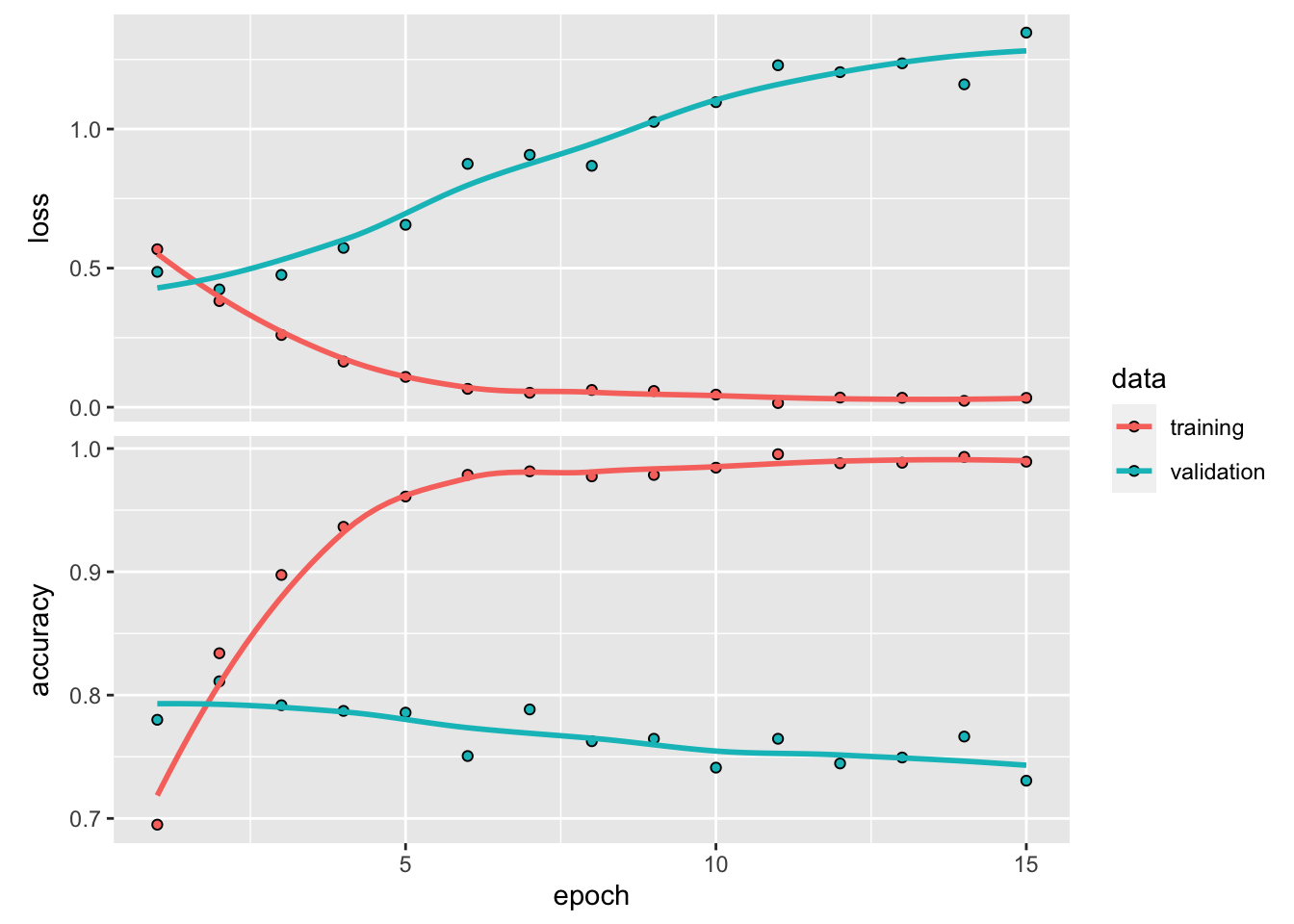
Visualize training process:
Testing
= model.evaluate(= batch_size,= 2
782/782 - 2s - loss: 1.3076 - accuracy: 0.7447 - 2s/epoch - 3ms/step
print ('Test score:' , score)
Test score: 1.307623028755188
print ('Test accuracy:' , acc)
Test accuracy: 0.7446799874305725
<- model %>% evaluate (batch_size = batch_size
cat ('Test score:' , scores[[1 ]])cat ('Test accuracy' , scores[[2 ]])